
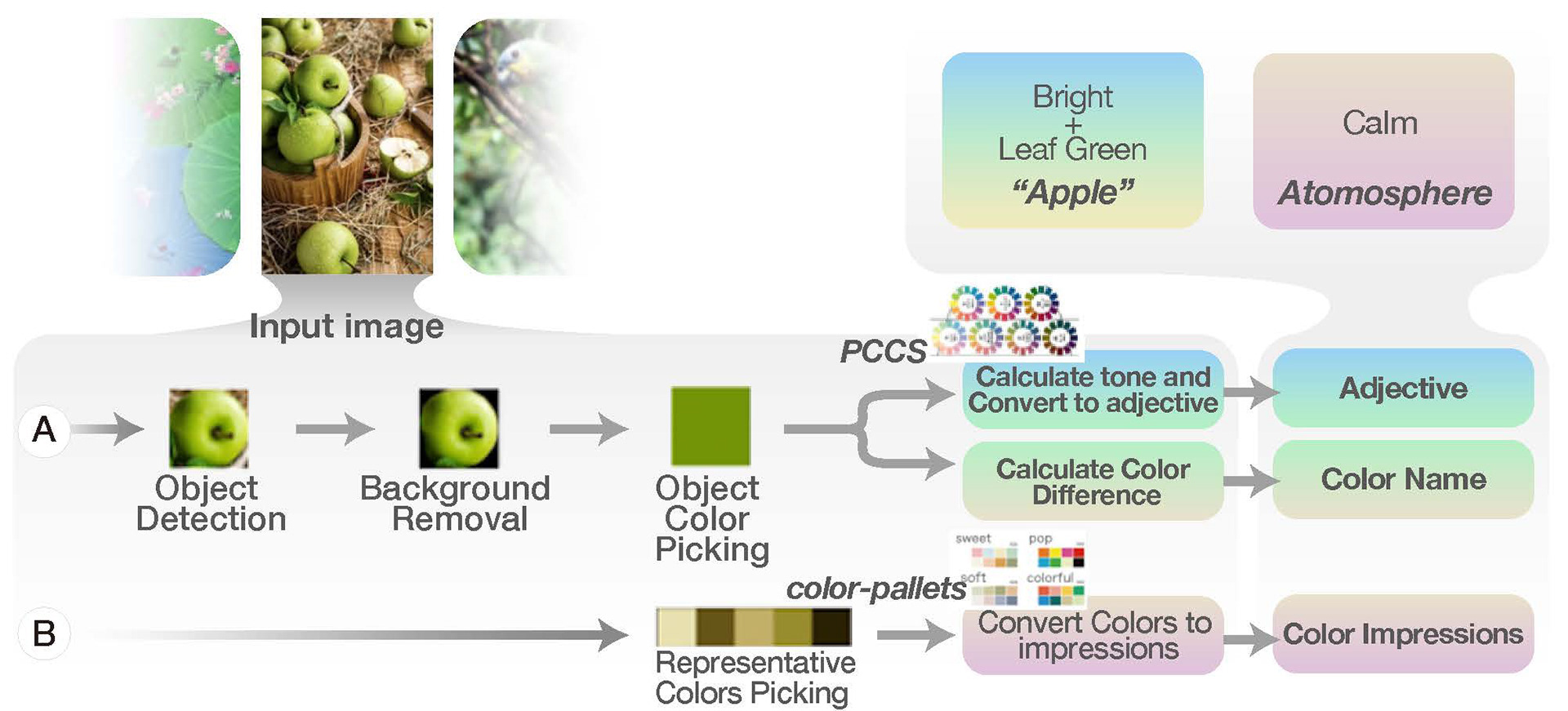
視覚障がい者にとって、風景や視覚芸術を理解することは困難です。2010年代以降、視覚障がい者のコンテンツ理解を深めるために、視覚情報を触覚や聴覚情報に変換する技術開発が進められています。このような背景から、画像認識技術からユーザーの周囲を描写するアプリケーションも開発されています。 しかし、これらのアプリケーションでは、色彩に関する記述が少ないため、視覚障がい者が風景や視覚芸術を楽しむには不十分なのが現状です。そこで、本研究では、過剰な機能からユーザーを混乱させる要素がないことに着目し、視覚障がい者向けの説明の追加や視聴体験の実験を行いました。
まず、日本語音声説明の解析から、形や大きさに比べて色の説明が多いことを発見し、実装したシステムで色の説明を追加生成しました。 次に、17名の視覚障がい者を対象に実験を行い、実装した情景描写システムの評価を行いました。その結果、「色を想像できるようになった」という意見があった。しかし、説明がわかりにくいという意見もありました。その意見には3つのタイプがあった。1.未知の言葉、抽象的な言葉 2.不自然な言葉の組み合わせ 3.最初の想像から大きくずれている。 今後の展望として、音声ガイドなどの障害者向け説明文をもとにコーパスを作成し、語句の対応や生成された文の順序を考慮した文を生成することで、視覚障害者が風景を詳細かつ瞬時に理解することをうまく支援することを目指しています。
まず、日本語音声説明の解析から、形や大きさに比べて色の説明が多いことを発見し、実装したシステムで色の説明を追加生成しました。 次に、17名の視覚障がい者を対象に実験を行い、実装した情景描写システムの評価を行いました。その結果、「色を想像できるようになった」という意見があった。しかし、説明がわかりにくいという意見もありました。その意見には3つのタイプがあった。1.未知の言葉、抽象的な言葉 2.不自然な言葉の組み合わせ 3.最初の想像から大きくずれている。 今後の展望として、音声ガイドなどの障害者向け説明文をもとにコーパスを作成し、語句の対応や生成された文の順序を考慮した文を生成することで、視覚障害者が風景を詳細かつ瞬時に理解することをうまく支援することを目指しています。
It is difficult for the visually impaired to understand landscapes and visual arts. Since 2010s, technology development for converting visual information into tactile or auditory information has been investigated to improve the contents understanding of visually impaired.From this background, applications describing user’s surroundings from image recognition technology has been developed. However, these applications currently generate little description of color, which is insufficient for visually impaired people to enjoy landscapes and visual arts. Therefore, in this research, we have added additional explanation and experimented the viewing experience for the visually impaired on the focus to avoid elements that confuse the user from excessive amount of features.
First, we have discovered that colors are described intensively comparing to shapes and sizes from analyzing Japanese audio descriptions, and generated additional description of them in the implemented system. Next, we have evaluated the implemented scene describing system by conducting experiment on 17 visually impaired. As a result, there was an opinion that it became possible to imagine colors. Nevertheless, there were some opinions that explanation was difficult to understand. These were three types of opinions. 1.Unknown or abstract words 2.Unnatural combination of words 3.The big shift from the first imagination. As the future prospect, we aim to well assist the visually impaired to understand the landscape in detail and instantly by generate a corpus based on explanatory texts for people with disabilities, such as audio guides, and to generate sentences that take into account word-for-word affiliation and the order of the generated sentences.
First, we have discovered that colors are described intensively comparing to shapes and sizes from analyzing Japanese audio descriptions, and generated additional description of them in the implemented system. Next, we have evaluated the implemented scene describing system by conducting experiment on 17 visually impaired. As a result, there was an opinion that it became possible to imagine colors. Nevertheless, there were some opinions that explanation was difficult to understand. These were three types of opinions. 1.Unknown or abstract words 2.Unnatural combination of words 3.The big shift from the first imagination. As the future prospect, we aim to well assist the visually impaired to understand the landscape in detail and instantly by generate a corpus based on explanatory texts for people with disabilities, such as audio guides, and to generate sentences that take into account word-for-word affiliation and the order of the generated sentences.
May 26. 2022
論文 https://doi.org/10.1007/978-3-031-06417-3_75
Chieko Nishimura, Naruya Kondo, Takahito Murakami, Maya Torii, Ryogo Niwa, Yoichi Ochiai . (2022). How See the Colorful Scenery?: The Color-Centered Descriptive Text Generation for the Visually Impaired in Japan. In: Stephanidis, C., Antona, M., Ntoa, S. (eds) HCI International 2022 Posters. HCII 2022. Communications in Computer and Information Science, vol 1580. Springer, Cham. https://doi.org/10.1007/978-3-031-06417-3_75